
Music Festival band finder with GPTScript
I love attending music festivals, and wanted to see if I could combine OpenAI’s API, GPTScript and Spotify to build an app that could look into the bands performing at some up coming music festivals and make some recommendations on bands that I might want to see based on my own preferences.
GPTScript is a scripting language designed to automate interactions with OpenAI’s language models. In this post, I’ll share how I used it to create a useful tool for music enthusiasts attending upcoming festivals to find bands they might like, and songs from those bands on Spotify.
I started with a script just for Coachella, but extended it to include Lollapalooza, Bottlerock, Jazz Fest, Glastonbury and Bonaroo. The script will use the music festival’s lineup to make personalized band recommendations along with song samples from Spotify. To skip ahead, here is the final script just for coachella and the final script for all the musical festivals. Also, here is the finished live app I’ve published on render.

Install GPTScript
The first thing we need to do is follow these instructions to install gptscript. I’m running on Linux where the installation step is simply:
curl https://get.gptscript.ai/install.sh | sh
I then set my OpenAI key to this environment variable:
export OPENAI_API_KEY=your-api-key
We will also need a variable for Brave Search token set for the search tool:
export GPTSCRIPT_BRAVE_SEARCH_TOKEN=your-api-key
Mission 1: Capturing the Coachella Lineup
Let’s start by creating our first tool to capture the upcoming coachella lineup. The simplest way to capture a website with GPTscript is using the built in sys.http.html2text? tool. As the name implies it converts an http request into text that the AI can process.
Using coachella’s official lineup page https://www.coachella.com/lineup I created a tool like this:
[coachella.gpt]
---
name: download-coachella-content
description: Content of coachella lineup page
tools: sys.http.html2text?
Visit the page "https://www.coachella.com/lineup" and pull all the names of upcoming bands playing there. Output to console.
Running this script with gptscript coachella.gpt doesn’t produce any results. What happened?
Coachella loads its content dynamically, so we’ll need a different solution. We could create a python script that uses selenium, which I did here but coachella’s website has another problem of being slow and sometimes not returning data at all. So I found another website that publishes the Coachella lineup each year called pitchfork.com. The new tool uses the brave search feature:
[coachella.gpt]
---
name: download-coachella-content
description: Downloads the content of coachella lineup page into file lineup.txt
tools: sys.http.html2text?, github.com/gptscript-ai/search/brave
Search for the upcoming coachella lineup based on a specific year (either this year or next year if we passed it) and find the pitchfork.com page for it.
The search should look like "coachella lineup site:pitchfork.com". Take that url, visit the page and output the bands you find to console
We run this again with gptscript coachella and see a list of bands:
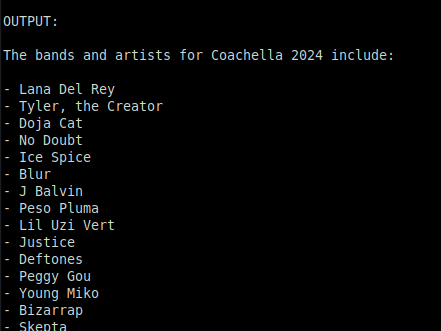
Mission 2: Saving the Lineup
What if we want to save the lineup and use it for later? For that, we’ll need to use the sys.write tool.
After we add the tool to our tools list we simply tell our script to write to a given filename as shown below:
[coachella.gpt]
---
name: download-coachella-content
description: Downloads the content of coachella lineup page into file lineup.txt
tools: sys.http.html2text?, sys.write, github.com/gptscript-ai/search/brave
Search for the upcoming coachella lineup based on a specific year (either this year or next year if we passed it) and find the pitchfork.com page for it. The search should look like "coachella lineup site:pitchfork.com".
Take that url, visit the page and save all the bands playing at coachella in lineup.txt.
After running the script, voila, we find lineup.txt written with every band present.
Mission 3: Getting Band Recommendations
First we’ll need input from the user about bands or genres they like. Let’s just call that input "bands".
We’ll declare the args for the main tool with args: bands: A list of bands you like.
Next we need to read the contents of lineup.txt. To do this we will invoke the sys.read tool. As the name implies sys.read is for reading a file.
The main tool at the top of the script manages the smaller tools we’ve created. Note that the main tool doesn’t require a name parameter.
[coachella.gpt]
description: "Make band suggestions at Coachella based on input"
tools: download-coachella-content, find-similar-bands, sys.read, sys.write
args: bands: A list of bands or genres of music you like
Take in user input an output a list of the same + similar bands playing at coachella that the user might like.
---
name: find-similar-bands
description: Finds similar bands from concert
args: lineup.txt: Concert band lineup file
args: bands: A list of bands or genres of music you like
tools: sys.read, sys.write
You are a music expert. You know all abouts bands, music genres and similar bands. Look through each band/artist in lineup.txt to find all bands in lineup.txt that the user might like based on the "bands" input.
Write all the bands you find into matches.txt.
---
name: download-coachella-content
description: Downloads the content of coachella lineup page into file lineup.txt
tools: sys.http.html2text?, sys.write, github.com/gptscript-ai/search/brave
Search for the upcoming coachella lineup based on a specific year (either this year or next year if we passed it) and find the pitchfork.com page for it. The search should look like "coachella lineup site:pitchfork.com".
Take that url, visit the page and save all the bands playing at coachella in lineup.txt.
After running the script we see this output:
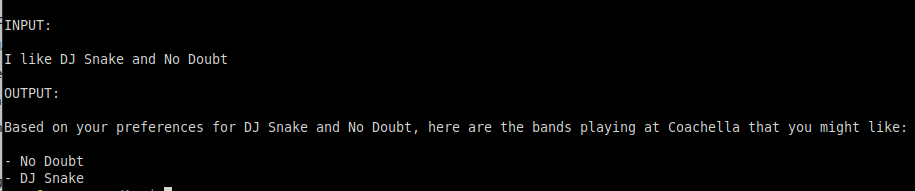
That has only the exact bands we mentioned and no additional suggestions which is not what we want.
To solve this we’ll introduce the concept of LLM temperature. The temperature setting in large language models (LLMs) affects the model’s output randomness. A low temperature (closer to 0) makes the model’s responses more predictable and deterministic, whereas a higher temperature (closer to 1.0) leads to more varied and sometimes more creative responses. GPTScript defaults to 0 temperature, so we will set it to 0.3 to increase it and see what happens.
[coachella.gpt]
tools: sys.read, sys.write
temperature: 0.3
After running the script again I see matches.txt filled with bands.
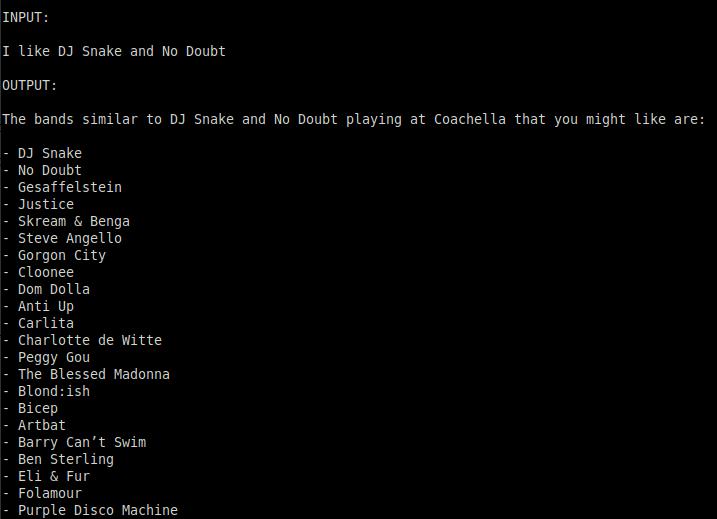
Better! But now I’m seeing about a dozen bands and sometimes not the original bands from our input. Let’s add some language to our prompt to make the output more specific
...find all bands in lineup.txt that the user might like based on the "bands" input. This will include the specific bands from the input as well as several suggestions based on those band preferences
Mission 4: Fetching Songs from Spotify
To fetch songs on Spotify I first created a simple Python script songs.py.
Then I integrated the script into the get-spotify-songs tool like this:
[coachella.gpt]
---
name: get-spotify-songs
description: get songs from url of spotify artist
args: url: spotify url for an artist
tools: github.com/gptscript-ai/search/brave
temperature: 0.2
#!python3 songs.py "$url"
But when we run our script we see No Doubt’s songs are for Franz Ferdinand!

This appears to be a hallucination. Since we didn’t specifically tell ChatGPT how to find the artist’s spotify artist pages, it just pulled from its training material. This seems to not be the most reliable method for finding the spotify page.
Luckily, I discovered that someone had already created a gptscript tool for the Spotify api (credit to Grant Linville).
For the Spotify api we use the pre-made spotify.yaml file which contains the OpenAPI tool definition. This also requires us to OAuth into Spotify as explained here.
Now we update our tool get-spotify-songs like this:
[coachella.gpt]
---
name: get-spotify-songs
description: get songs for each artist or band
args: bands: a list of band
args: numberOfSongs: number of songs to obtain per band or artist
tools: ./spotify.yaml, sys.read, sys.write
temperature: 0.2
internal prompt: false
For all bands in the list find 3 spotify song for each. Name and url. For each band wait 1 second between each api call. Write the bands+songs output to band_spotify.txt file; create it if it doesn't exist.
Upon running the script, we see songs output for every band we found in matches.txt. The AI chose the right tool to use from spotify.yaml without us needing to tell it.
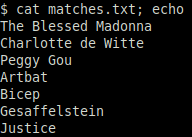
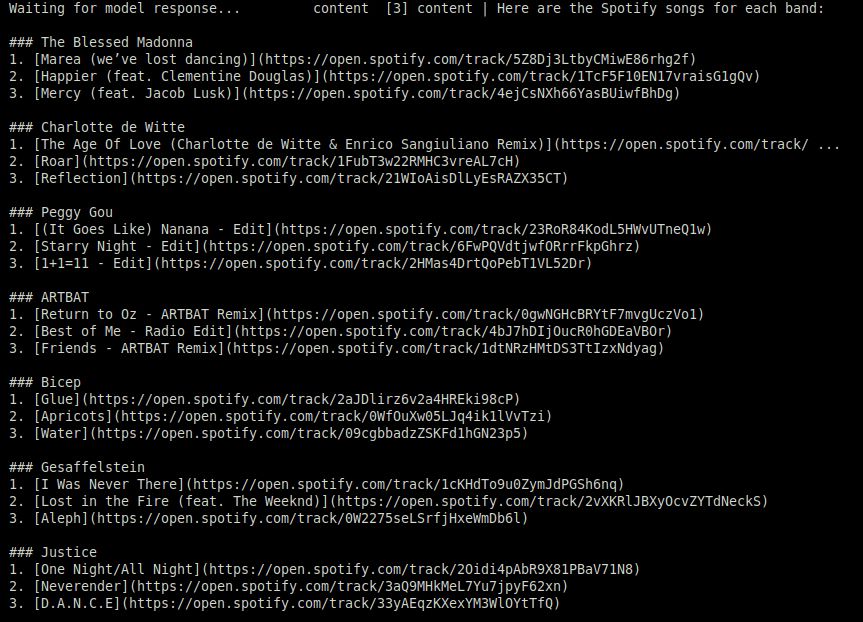
Mission 5: Ensure Reliable Outputs
After 3 runs of the script the AI started returning only a single output rather than all bands found in matches.txt.
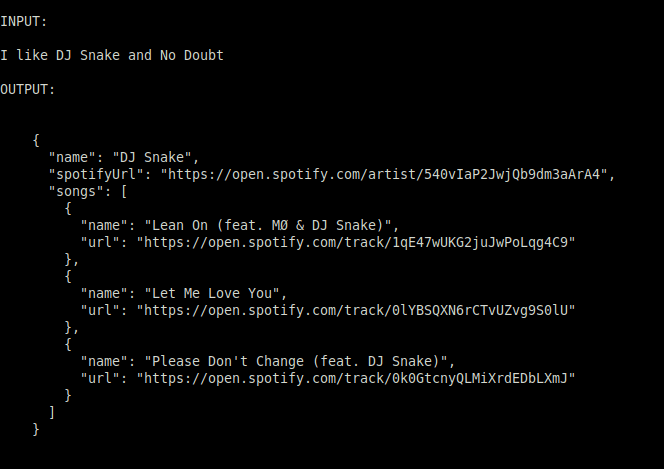
However, matches.txt has 10 bands which means the AI is abridging the final output.
After trying a few different fixes, I added the magic words "do not abridge the list" to the prompt regarding the final output and it worked again. Apparently sometimes the best approach is telling AI what not to do, even if it would seem obvious to a human.
Mission 6: Improve performance
Right now our script is taking upwards of 4 minutes to run, so let’s see what we can change to increase performance.
Not writing to file
One performance hit appears to be writing to file. Let’s replace language like "write to matches.txt" with "reference this data as $matches". $matches is just a variable in memory, rather than a file. This saves about a minute of run time replacing 3 text files with variables.
Reusing lineup.txt file
And since lineup.txt is already written (and should be valid for up to a year) we don’t need our script to obtain it each run. So we will remove that code and just rely on lineup.txt already existing
Reduce the number of tools being called
Another performance boost comes from reducing the number of tools being called. I noticed that there is significant overhead with each additional tool in the call chain. I started playing around with removing or combining some of the tools I declared. I reduced my subtools down to just one called get-spotify-songs, and the main tool now handles recommendations and simply pulls the coachella lineup from an existing lineup.txt we created using GPTScript. That saves about another minute.
Tighten up the language on inputs and output
Lastly, I’ve tightened up the language to be specific about the input going into the tool we want to use "pass $bands_at_coachella to the get-spotify-songs tool" for instance.
Our final couchella script becomes:
[coachella.gpt]
tools: get-spotify-songs, sys.read
args: bands: A list of bands you like.
description: find bands the user might like at coachella along with 3 songs each
json response: true
temperature: 0.2
You are a music expert, concert expert, and web researcher.
Perform the following tasks in order:
Read lineup.txt and find the exact bands from user's input that are also in lineup. You will call that data $exact_matches. $exact_matches will be empty unless the band name is found in both lineup and input.
Then based on the user input, recommend several bands from lineup.txt which are in the same genre (up to 5 similar artists). You will call that data $recommendations.
Next combine $exact_matches and $recommendations into $bands_at_coachella.
Then pass $bands_at_coachella to the get-spotify-songs tool to find $spotify_bands.
For all those $spotify_bands found return that output in json format like so: {"bands": [{ "name": <band name string>, "spotifyUrl": url_value, songs: [{"name": value, "url": song_url_value}] },...]}.
Do not abridge the list or miss any items from $spotify_bands. Return the final output
---
name: get-spotify-songs
description: get songs for each artist or band
args: bands: a list of band
args: numberOfSongs: number of songs to obtain per band or artist
tools: search from ./spotify.yaml,get-an-artists-top-tracks from ./spotify.yaml, sys.read
temperature: 0.3
internal prompt: false
For all the $bands given, find 3 spotify song for each -- song name and url. Call that dataset $spotify_bands.
Mission 7: Launching the App
I created a simple Rails web app for our tool which calls the script and displays the results in list format.
The end result looks like this:
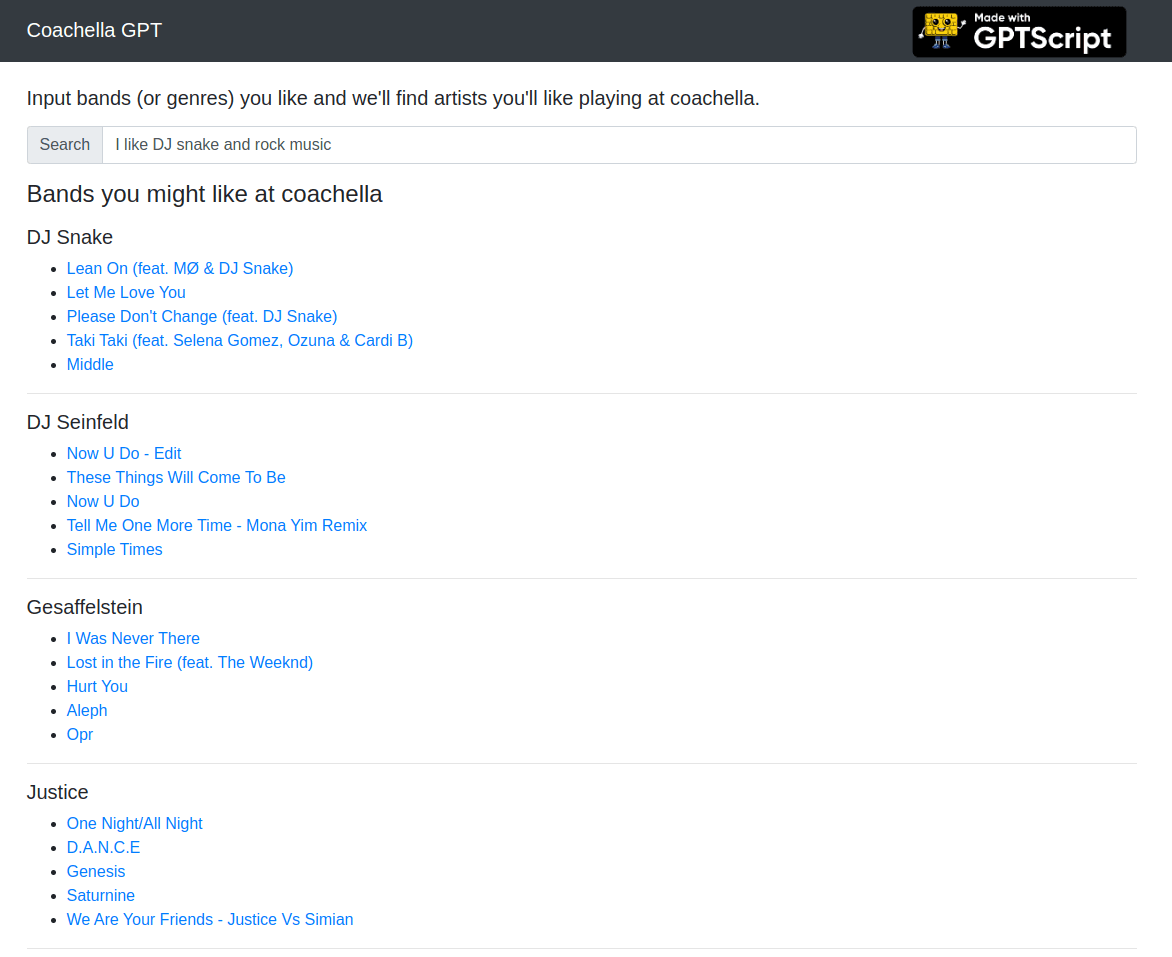
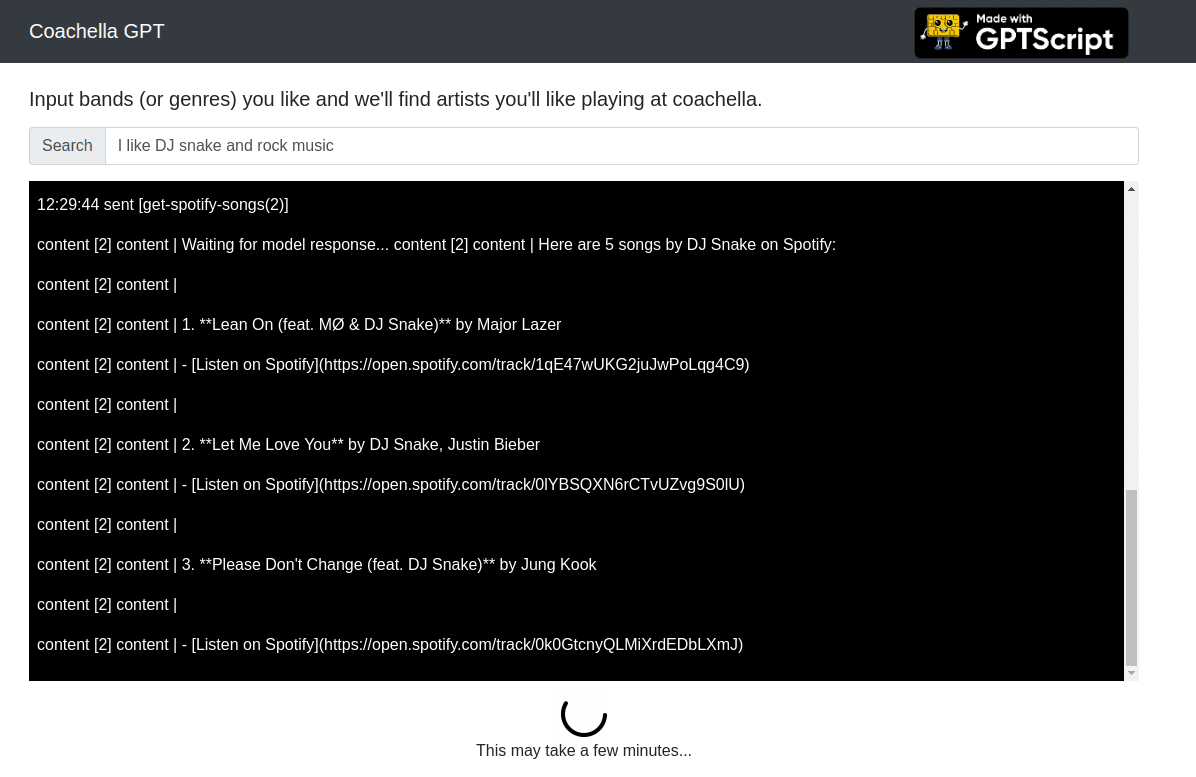
The deployment is live here to try. It takes a minute to get results right now, so we added a console output from our gptscript command to show what is happening in real time.
Mission 8: Adding more venues
Now that we’ve done this for Coachella we can repeat the process for other music festivals:
- Lollapalooza
- Jazz Fest
- Glastonbury
- Bottlerock
- Bonnaroo
I’ll spare you the details of creating each script to produce lineup.txt files for each music festival. You can find those scripts here in the respective venue folder.
But now that we have a lineup file for each venue we will modify those files to have a prefix like to $venue_lineup.txt. So for example coachella would be coachella_lineup.txt, Jazz Fest will be jazz_fest_lineup.txt, etc.
Our final script now looks like:
tools: get-spotify-songs, sys.read
args: bands: A list of bands you like.
args: venue: place where the event is organized
description: find bands the user might like at coachella along with 3 songs each
json response: true
temperature: 0.2
You are a music expert, concert expert, and web researcher.
Perform the following tasks in order:
In case venue argument is present, lineup file name is ${venue}_lineup.txt. Otherwise, lineup file name is lineup.txt
Read the lineup file and find the exact bands from user's input that are also in lineup. You will call that data $exact_matches. $exact_matches will be empty unless the band name is found in both lineup and input.
Then based on the user input, recommend several bands from the lineup file which are in the same genre (up to 5 similar artists). You will call that data $recommendations.
Next combine $exact_matches and $recommendations into $bands_at_venue.
Then pass $bands_at_venue to the get-spotify-songs tool to find $spotify_bands.
For all those $spotify_bands found return that output in json format like so: {"bands": [{ "name": <band name string>, "spotifyUrl": url_value, songs: [{"name": value, "url": song_url_value}] },...]}.
Do not abridge the list or miss any items from $spotify_bands and return the final output in one json object.
---
name: get-spotify-songs
description: get songs for each artist or band
args: bands: a list of band
args: numberOfSongs: number of songs to obtain per band or artist
tools: search from ./spotify.yaml,get-an-artists-top-tracks from ./spotify.yaml, sys.read
temperature: 0.3
internal prompt: false
For all the $bands given, find 3 spotify song for each -- song name and url. Call that dataset $spotify_bands.
When using the spotify api do not repeat an api call more than 3 times.
We also need to update our script to take in a ‘venue’ param. We will designate it with –venue and our normal input with –input. Our updated command looks like
command = "GPTSCRIPT_API_SPOTIFY_COM_BEARER_TOKEN=#{spotify_token} gptscript --disable-cache" + " " + "coachella.gpt" + " --input " + params[:input] + " --venue " + params[:venue] || "coachella"
Finally we will update the front end to have a select for venue which gets passed in as params[:venue].
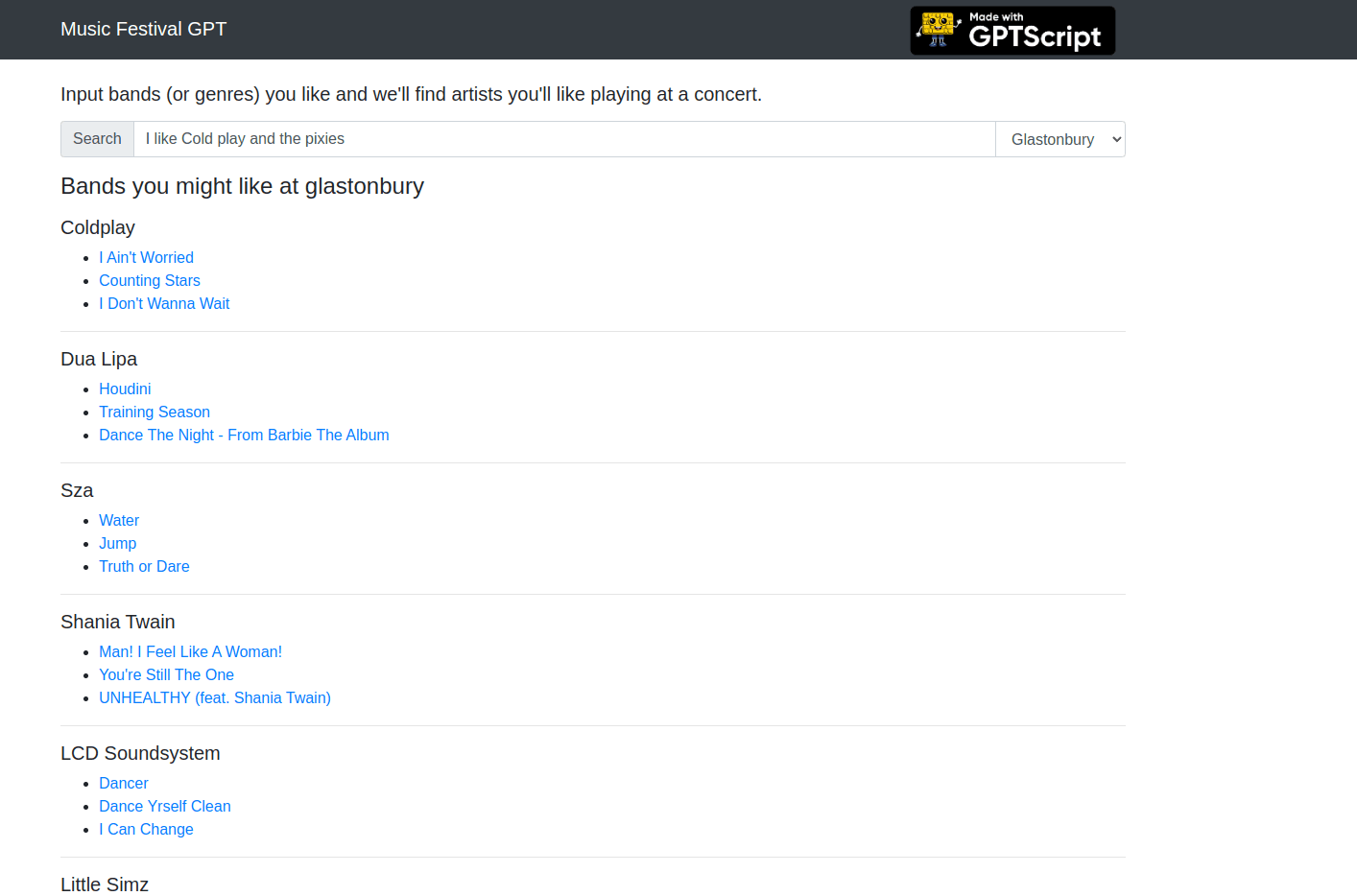
When we test our app we find it is able to give recommendations for each venue just as easily as the first:
The full code for the music festival app is here
Look how far we’ve come in such a short time. This tool shows the power of AI integrations. We didn’t have to write a single api call or any complex logic to find / compare similar bands, find songs for bands, or pull the lineup from Coachella. I will definitely be integrating GPTScript into my future workflows.