What Is Retrieval Augmented Generation (RAG)?
Retrieval Augmented Generation (RAG) is a machine learning technique that combines the power of retrieval-based methods with generative models. It is particularly used in Natural Language Processing (NLP) to enhance the capabilities of large language models (LLMs). RAG works by fetching relevant documents or data snippets in response to queries, which are subsequently used to generate more accurate and contextually relevant outputs.
The hybrid approach utilizes a retriever model to sift through external data sources and a generator model that processes retrieved information to construct responses. This method helps to bridge the gap between vast data reserves and the need for precise and relevant linguistic generation, making RAG particularly suitable for tasks requiring both informed responses and creative handling of language. This is part of an extensive series of guides about machine learning.
The Benefits of Retrieval-Augmented Generation
RAG has compelling benefits for modern NLP applications, in particular systems based on large language models:
- Up-to-date and accurate response: RAG ensures that generated responses are not only contextually relevant but also reflect the most current data. By accessing and integrating external information on the fly, RAG systems can provide updated answers based on the latest available information, even if this information was not present in the model’s training data.
- Reducing inaccurate responses, or hallucinations: RAG reduces the issue of “hallucinations”, where language models generate plausible but factually incorrect or misleading information. By anchoring the generation process in retrieved documents that are verified and relevant, the system minimizes the chances of producing false content. This retrieval layer ensures that generated content can be traced to a source of truth.
- Efficient and cost-effective: Utilizing RAG can be more efficient and cost-effective compared to training or fine tuning models for each application. By combining retrieval mechanisms with generative capabilities, the same base model can adapt to various scenarios based on the external data it accesses. In addition, the retriever component filters available data to the necessary minimum, speeding up response time and reducing inference cost.
The Retrieval-Augmented Generation Process
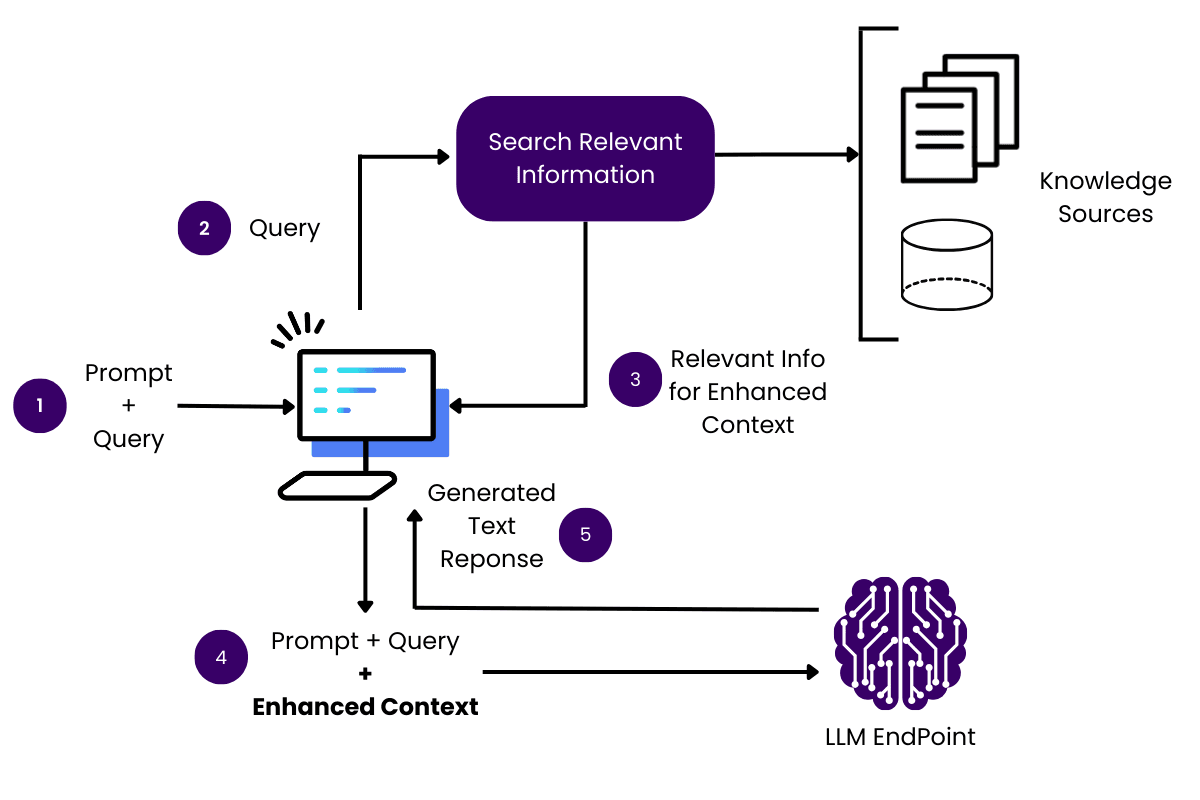
1. Receive a Prompt / Query
Retrieval-Augmented Generation (RAG) begins when the system receives a prompt or query from a user. This could range from a specific question, like asking for the latest news on a topic, to a broader request for creative content generation.
Upon receiving the prompt, the RAG system processes and understands the user’s intent, which sets the direction for the subsequent retrieval phase. This initial step is crucial as it determines what type of information the system should look for in a large pool of external data.
2. Search Relevant Source Information
Once the prompt is received and parsed, the RAG system activates its retriever component to search for relevant information across various external databases and sources. This may involve sifting through updated news articles, academic papers, or any data repositories prepared for use of the model.
The goal here is to find content that matches or relates to the query. This search is powered by algorithms that can parse the semantic meaning of the user’s request, ensuring that the retrieval is as relevant as possible.
3. Retrieve Relevant Information for Added Context
Following the search, the system retrieves the most relevant documents or pieces of information identified during the initial search. This step is vital as it provides the raw material that will feed into the generation phase.
The quality of retrieved data directly influences the accuracy and relevance of the system’s final output. Therefore, the retrieval process is optimized to select information that not only matches the query but is also from credible and authoritative sources.
4. Augment the Prompt with Added Context
With the relevant data retrieved, the RAG system augments the original prompt with this new information. This enriched prompt now contains additional context that enhances the understanding of the user’s request.
For instance, if the query was about recent scientific advancements in robotics, the augmented prompt may include snippets from the latest research papers or expert blogs. This augmentation process allows the generative model to produce responses that are not only relevant but also enriched with up-to-date facts and data, which were not included in the LLM’s training data.
5. Submit to Large Language Model
At this stage, the augmented prompt is fed into a large language model. The LLM, which has been trained on vast amounts of text, uses its generative capabilities to synthesize information from the augmented prompt into a coherent and contextually relevant response. This response could be an answer to a question, a summary of information, or even creative content, depending on the nature of the initial prompt.
6. Deliver Improved Response to the User
Finally, the generated response is polished and delivered back to the user. This output aims to be more accurate, informative, and contextually relevant than what could be produced by a simple generative model without the augmented input.
The integration of retrieved data ensures that the responses are not only based on the language model’s training but are also informed by real-time data and specific context provided by the user’s initial query. This enhances the overall user experience by providing answers that are both accurate, timely, and more closely tailored to their specific needs.
Learn more in our detailed RAG tutorial.
Retrieval-Augmented Generation vs. Semantic Search vs. Fine Tuning
Retrieval-Augmented Generation differs from semantic search and fine-tuning in several key aspects:
Semantic search focuses solely on retrieving the most relevant information based on query understanding—it does not involve any generative process. Semantic search is effective for direct information retrieval tasks but lacks the ability to synthesize or expand upon the found data.
Fine-tuning involves adjusting a pre-trained model’s parameters to perform better on specific tasks. While this can lead to improved performance in certain applications, it does not provide the ability to incorporate real-time data like RAG does. It is also much more complex and computationally intensive.
RAG combines the strengths of both worlds. It uses retrieval to ensure data relevance and freshness, while the generative component allows for creative and adaptive output generation.
It should be noted that many RAG mechanisms use semantic search as part of the retrieval mechanism. For example, they can take portions of the user’s prompt or query and use them to semantically search knowledge bases and return relevant information snippets.
Learn more in our detailed guide to RAG vs Fine Tuning.
RAG Use Cases
Question Answering
In the realm of question answering, RAG systems can dramatically enhance performance by incorporating the most accurate and up-to-date information in their responses. For instance, a RAG model can retrieve the latest research articles or data reports in response to medical inquiries. Bridging the latest findings directly into the answers not only boosts the relevance of the responses but also ensures that they are grounded in factual data.
This application of RAG can be critically important in areas where timely and reliable information can affect health outcomes or policy decisions. By effectively merging retrieval and generation, RAG provides a robust framework for developing advanced question-answering systems.
Summarization
RAG is also adept at generating concise summaries from large sets of documents. In use cases like executive briefings where decision-makers need condensed information from multiple reports, RAG can fetch relevant documents based on the topic and synthesize a coherent summary. This process involves extracting the key points from each document and integrating them into a comprehensive overview.
By leveraging the retrieval capability, RAG ensures that the summaries are not only concise but also incorporate the most pertinent and current information available across the documents. This makes RAG particularly useful in corporate, legal, or academic settings where digesting large volumes of information effectively is crucial.
Conversational AI
In conversational AI, RAG can contribute to building more knowledgeable and context-aware chatbots and virtual assistants. By retrieving information in real-time during a conversation, RAG-based models can provide responses that reflect the current context or user needs accurately. For instance, if a user asks about a recent event or a complex topic, the RAG model can quickly pull information from relevant sources to craft a well-informed reply.
This ability not only makes conversational agents appear more intelligent but also enhances user satisfaction by providing precise and timely information. RAG’s combination of retrieval and generation capabilities makes it ideal for applications where engaging and accurate dialogue is key.
Content Generation
RAG is highly effective in content generation tasks that require a blend of creativity and factual accuracy. This can include scenarios like generating articles, reports, social media posts, or even creative stories that need to embed accurate data or references. By using RAG, content creators can automate part of the creative process, ensuring that their outputs remain engaging while being reliably informed.
For example, when writing a technical article on a new scientific discovery, a RAG system can pull relevant studies and data to ensure that the content is factual. At the same time, the generative model can ensure that the narrative is coherent and stylistically appropriate.
Learn more in our detailed guide to RAG examples (coming soon)
Challenges and Limitations of Retrieval Augmented Generation
Despite the compelling benefits of RAG, the technology is still in its early days and faces several challenges.
Dependence on External Knowledge
One significant challenge of RAG is its dependence on the availability and quality of external knowledge sources. The effectiveness of a RAG model is directly tied to the comprehensiveness and accuracy of the data it can access. If the external data is incomplete, outdated, or biased, it can adversely affect the performance of the model.
Furthermore, the setup requires continuous updates and maintenance of the knowledge base to keep the system effective. This ongoing dependency on external data sources can be resource-intensive and requires robust data management strategies.
Computational Overhead
RAG systems also introduce additional computational overhead due to the need for real-time data retrieval and processing. Each query necessitates a retrieval operation, which must be performed quickly to maintain response times, especially in user-facing applications. This requirement can lead to higher computational costs and may necessitate more powerful hardware or optimized algorithms, compared to LLMs without a RAG mechanism.
The integration of retrieval and generation components needs to be highly efficient to prevent bottlenecks. Practitioners must carefully balance the depth of retrieval and the complexity of the generative model to ensure optimal performance without excessive computational demands.
Privacy and Compliance Concerns
Implementing RAG in certain domains may raise privacy and compliance issues, especially when handling sensitive or personal data. Since RAG models interact with extensive external databases, ensuring that all data handling conforms to relevant laws and regulations is crucial.
In industries like healthcare or finance, where data privacy is paramount, deploying RAG solutions necessitates rigorous security measures and compliance checks. Failure to adequately address these concerns can result in legal penalties and damage to trust and credibility.
Strategies for RAG Performance Optimization
Engineer the Base Prompt to Guide the Model’s Behavior
Optimizing RAG performance requires careful engineering of the base prompt used in the generative model. The base prompt sets the initial direction for the generation process, and its design can influence how effectively the model integrates retrieved information.
Prompts should be crafted to clearly specify the desired output while being flexible enough to incorporate diverse data dynamically retrieved. This requires a deep understanding of both the model’s generative capabilities and the nature of the data being retrieved, ensuring that the prompts effectively harness the system’s full potential. Testing is essential to see if the base prompt, combined with a variety of user prompts and retrieved data, provides useful outputs.
Embed Metadata to Enable Filtering and Context Enrichment
Another effective strategy is to embed rich metadata within the external data sources. This metadata can help the retrieval system filter and prioritize the data more effectively, leading to quicker and more relevant fetches. Metadata can include information like source reliability, content freshness, or relevance scoring based on prior engagements.
Enriching the data with metadata not only helps streamline the retrieval process but also enhances the overall quality of the generated outputs, as the system can make more informed decisions about which data to retrieve.
Explore Hybrid Search Techniques
To optimize retrieval, exploring hybrid search techniques that combine multiple retrieval methodologies can be beneficial. This might involve integrating keyword-based search with semantic search capabilities or combining vector-based techniques with traditional database queries.
Such hybrid approaches can harness the strengths of each method, providing a more robust retrieval mechanism that can adapt to different types of queries and data environments. This flexibility can significantly enhance the performance of RAG systems, especially in complex or varied information landscapes.
Implement Recursive Retrieval and Sophisticated Query Engines
Recursive retrieval involves performing multiple rounds of retrieval based on initial results to refine and improve the data fetched. This iterative process can help hone in on the most relevant information, especially in complex query scenarios.
Sophisticated query engines can interpret and decompose complex queries into manageable components, optimizing the retrieval process for each part. Such capabilities ensure that even the most complicated queries are handled effectively, boosting the system’s utility and flexibility.
Evaluate and Adjust Chunk Sizes
Optimizing the performance of a RAG system involves careful management of the data chunks used in the retrieval process. By adjusting the size and scope of these chunks, practitioners can significantly affect both the speed and accuracy of the retrieval.
Smaller chunks might increase precision but could also lead to higher processing times, whereas larger chunks might speed up retrieval at the cost of providing too much information, which diffuses the context available to the LLM. Thus, it’s essential to experiment with different chunk sizes to find an optimal balance that suits the specific application.
Fine-Tune Search Algorithms to Balance Accuracy and Latency
Fine-tuning the underlying algorithms used for vector searches is crucial for optimizing retrieval accuracy while maintaining acceptable latency levels. Vector search algorithms, which are often at the core of RAG retrieval systems, need to be calibrated carefully to ensure they are neither too broad nor too narrow in their data retrieval.
This tuning involves adjusting parameters like vector dimensionality, indexing strategies, and similarity thresholds. Proper calibration can significantly improve the speed and relevance of search results, thereby enhancing the overall effectiveness of the RAG system.
Building RAG Systems with Acorn
The core logic behind RAG can be implemented in one GPTScript statement.Try it out in GPTScript today – get started at gptscript.ai and check out the RAG use cases in GPTScript here.
See Additional Guides on Key Machine Learning Topics
Together with our content partners, we have authored in-depth guides on several other topics that can also be useful as you explore the world of machine learning.
Auto Image Crop
Authored by Cloudinary
- Auto Image Crop: Use Cases, Features, and Best Practices
- 5 Ways to Crop Images in HTML/CSS
- Cropping Images in Python With Pillow and OpenCV
LLM Prompt Engineering
Authored by Acorn
- Prompt Engineering: Techniques, Uses & Advanced Approaches
- Prompt Engineering in ChatGPT: 9 Proven Techniques
- 8 Prompt Engineering Examples for Common NLP Tasks
Fine Tuning LLM
Authored by Acorn