What Is Mistral 7B?
Mistral 7B is a large language model (LLM) developed by Mistral AI, featuring 7.3 billion parameters. This model has been open-sourced under the Apache 2.0 license, offering the community free and unrestricted access to its capabilities.
The model is recognized for its exceptional performance, surpassing other models of similar size in benchmarks. Notably, it achieves higher scores than Meta’s Llama 2 13B model and is competitive with the much larger Llama 70B model, despite having nearly half the number of parameters of the Llama 2 13B.
Mistral 7B’s accessibility and performance make it a valuable resource for researchers and developers in AI, particularly for those interested in training and running LLMs with constrained resources. A common use case of the model is to fine-tune it using Parameter-Efficient Fine-Tuning (PEFT) techniques like LORA.
Access the model on Hugging Face: https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2
Mistral 7B Architecture
Mistral 7B employs an advanced transformer architecture, with enhancements in attention mechanisms and improved memory optimization. These architectural enhancements enable Mistral 7B to achieve faster processing speeds and lower latency at inference time, handling up to approximately 131,000 tokens in its attention span by the final layer.
Here are some of the components:
- Sliding Window Attention (SWA): SWA limits each token to attend to a maximum of W tokens from the previous layer, where W is set at 3. This restriction in attention span helps manage the quadratic growth in computational complexity typically seen with larger models, as well as alleviating memory load by preventing an increase in cache size beyond this window.
- Rolling Buffer Cache: The cache holds a fixed number of keys and values (W), with new entries replacing the oldest ones once the cache exceeds this size. This fixed window size significantly reduces memory requirements—up to eightfold—without degrading model performance.
- Pre-fill and chunking: Aimed at optimizing the generation process for long sequences, the prompt is pre-filled into the cache, potentially in segmented chunks based on the window size. This enables more efficient attention computation during token generation. It speeds up processing and conserves memory by reducing the length of sequences that need to be stored in memory at any one time.
Mistral 7B vs. LLaMA
Mistral 7B is most commonly compared to LLaMA, a competing open source LLM created by Meta. Mistral 7B demonstrates significant advantages over various models in the LLaMA family, especially when it comes to performance metrics.
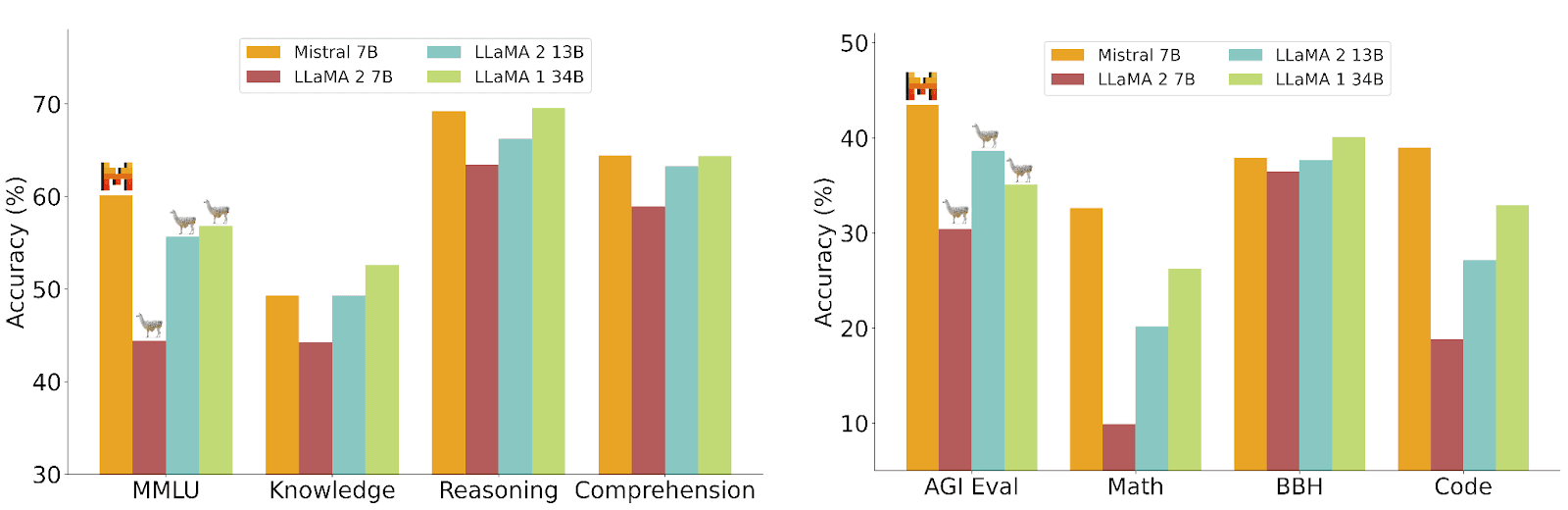
Source: Mistral
{kind=link}
Here is a summary of benchmark results reported by Mistral, comparing the Mistral 7B model to its closest competitor, LLaMA 2:
- Commonsense reasoning: Mistral 7B excels in commonsense reasoning, outperforming LLaMA 2 13B on tasks like HellaSwag, Winogrande, PIQA, SIQA, OpenbookQA, ARC-Easy, ARC-Challenge, and CommonsenseQA.
- World knowledge: In world knowledge benchmarks, such as NaturalQuestions and TriviaQA, Mistral 7B maintains a competitive edge. LLaMA 2 70B has better performance in some instances, but Mistral 7B is highly effective given its smaller size and parameter count.
- Reading comprehension: Mistral 7B surpasses LLaMA models in reading comprehension tasks, including BoolQ and QuAC.
- Mathematics: Mistral 7B performs well in GSM8K and MATH benchmarks, utilizing its architecture to handle complex calculations and problem-solving tasks effectively.
- Code: Mistral 7B shows good performance in coding tasks, closely approaching the capabilities of CodeLLaMA 7B on benchmarks like Humaneval and MBPP.
- Aggregated benchmark results: Popular aggregated benchmarks, such as MMLU, BBH, and AGI Eval, show that Mistral 7B matches or exceeds the performance of larger LLaMA models.
- Cost-performance efficiency: Mistral 7B offers a significant advantage in terms of cost-performance efficiency. Its performance on reasoning, comprehension, and STEM reasoning tasks is equivalent to a LLaMA 2 model three times its size, with substantial memory savings and throughput gains.
Related content: Read our guide to Mistral 7B vs ChatGPT (coming soon)
How to Access Mistral 7B
There are several options for accessing Mistral 7B.
Direct Download
For those with experience in handling AI models, Mistral 7B can be accessed by downloading the model and its Docker images from the GitHub registry. Ensure that your setup includes a cloud virtual machine with at least 24GB of vRAM to run the model efficiently, though some configurations may only require 16GB with certain inference stacks.
Here is the magnet link to download the model weights: magnet:?xt=urn:btih:208b101a0f51514ecf285885a8b0f6fb1a1e4d7d&dn=mistral-7B-v0.1
Using Ollama
Ollama provides an effortless method to run large language models like Mistral 7B on macOS or Linux systems. You can get Ollama here.
After downloading Ollama, you can initiate the model using a simple command:
- For the default Instruct model:
ollama run mistral - For the text completion model:
ollama run mistral:text
This requires a minimum of 8GB of RAM.
Using Hugging Face
Hugging Face offers a straightforward way to deploy Mistral 7B on dedicated infrastructure. The Inference Endpoints service allows for 1-click deployment from the Model catalog, and the model runs on a single NVIDIA A10G GPU at approximately $1.30 per hour, with a latency of 33ms per token.
Learn more on the Hugging Face model page.
Using Perplexity AI
For those interested in using Mistral 7B in a conversational AI format, Perplexity AI offers an integration that allows Mistral 7B to answer questions via its search engine. Select mistral-7b-instruct from the model dropdown menu to start.
Getting Started with Mistral 7B
To begin working with Mistral 7B, follow these steps to set up and run the model. This guide covers installation, downloading the model, and running it for both demonstration and interactive purposes.
Installation
First, ensure you have the necessary dependencies installed. Use the following command to install them:
pip install -r requirements.txt
Downloading the Model
Next, download the Mistral 7B model weights using wget. Extract the downloaded tar file:
wget https://models.mistralcdn.com/mistral-7b-v0-1/mistral-7B-v0.1.tar -O mistral-7B-v0.1.tar
tar -xf mistral-7B-v0.1.tar
Running the Model
To run the model in a demonstration mode, use the following command. Replace /path/to/mistral-7B-v0.1/ with the path where the model is extracted:
python -m main demo /path/to/mistral-7B-v0.1/
For an interactive session where you can provide your own prompts, run:
python -m main interactive /path/to/mistral-7B-v0.1/
You can adjust the model’s behavior by changing parameters such as max_tokens and temperature. For example:
python -m main interactive /path/to/mistral-7B-v0.1/ --max_tokens 256 --temperature 1.0
Single-File Implementation
If you prefer a self-contained implementation, you can use one_file_ref.py. Execute it with:
python -m one_file_ref /path/to/mistral-7B-v0.1/
Running Large Models
For models too large to fit into a single GPU’s memory, use pipeline parallelism (PP) with torchrun. This is necessary for running larger configurations like Mixtral-7B-8x. The example below demonstrates 2-way PP:
torchrun --nproc-per-node 2 -m main demo /path/to/mixtral-7B-8x-v0.1/ --num_pipeline_ranks=2
By following these steps, you can set up and start using Mistral 7B for your AI projects.
Related content: Read our guide to how to use Mistral 7B (coming soon)
Fine Tuning Mistral 7B
Fine tuning MIstral 7B is a complex process. We’ll provide only the general steps and link to other resources that provide more information:
- Install dependencies: To start fine-tuning Mistral 7B, you first need to ensure that you have the necessary libraries installed. This includes packages such as Transformers, Accelerate, Torch, and other relevant tools.
- Prepare the dataset: Prepare a suitable dataset for fine-tuning. Begin by selecting a dataset that matches your specific task requirements, such as the mosaicml/instruct-v3 dataset. Once you have the dataset, format it appropriately by merging the prompt and response columns into a single formatted prompt.
- Load the base model: With the dataset ready, the next step is to load the Mistral 7B base model. To optimize memory usage and enhance processing speed, use a quantization technique that sets the model to use 4-bit precision. This approach reduces the model’s memory footprint, making it more efficient and suitable for environments with limited computational resources.
- Configure for fine-tuning: Before you start the fine-tuning process, configure the model for Low-Rank Adaptation (LoRA) training. LoRA focuses on using smaller matrices that represent the larger ones, thereby concentrating on the specific tasks you aim to improve. This technique not only optimizes the use of GPU resources but also accelerates the training process.
- Train the model: Set the necessary training parameters such as the number of training steps, batch size, learning rate, and other hyperparameters. Once these configurations are in place, begin the fine-tuning process. During this phase, the model’s weights are adjusted based on the dataset, enhancing its performance on the targeted task.
- Save and deploy the fine-tuned model: After the training process is complete, save the fine-tuned model. This makes it ready for deployment in various applications. If desired, you can also push the model to a model hub like Hugging Face. This step facilitates easy access, deployment, and sharing of the model, enabling others to leverage the fine-tuned version for their own tasks or projects.
For an in-depth review of fine-tuning with Mistral 7B, refer to the blog post by Maxime Labonne.
Building LLM Applications with Mistral 7B in Acorn
To download GPTScript visit https://gptscript.ai. As we expand on the capabilities with GPTScript, we are also expanding our list of tools. With these tools, you can build any application imaginable: check out tools.gptscript.ai and start building today.