What Is Meta LLaMA?
Meta LLaMA (Large Language Model Meta AI) is a family of autoregressive large language models developed by Meta AI. First released in February 2023, these models are designed for advanced natural language processing tasks.
The initial version of LLaMA provided model weights to the research community under a non-commercial license, allowing access on a case-by-case basis. However, subsequent versions, including LLaMA 2 and LLaMA 3, have been made more accessible, with licenses permitting some commercial use, broadening their applicability beyond academia.
LLaMA models are available in various sizes, ranging from 7 billion to 70 billion parameters. These models are built using transformer architecture, a standard in large language models, and are trained on diverse datasets consisting of publicly available information. This extensive training enables the models to perform well across multiple NLP benchmarks. This is part of an extensive series of guides about machine learning.
Meta LLaMA Models
Meta LLaMA 3
Meta’s LLaMA 3 series is a new generation of LLMs, with two model variants using 8B and 70B parameters (the B stands for billion). These models are designed for both general and specialized tasks, with a particular focus on optimizing dialogue interactions with improved helpfulness and safety.
LLaMA 3 models are based on an optimized transformer architecture. Available in both pretrained and instruction-tuned variants, they are fine-tuned through methods like supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF). This dual approach ensures that the models align closely with user expectations for responsiveness and secure interactions.
LLaMA 3 was trained on a dataset comprising over 15 trillion tokens from publicly available sources. The models also include enhancements from instruction datasets and more than 10 million human-annotated examples, providing a robust base for generating relevant and context-aware responses. Training leveraged Meta’s custom libraries and the Research SuperCluster, with further processes handled on third-party cloud compute platforms.
On standard industry benchmarks, LLaMA 3 models have demonstrated superior performance compared to earlier versions like LLaMA 2, especially in categories such as general knowledge, reading comprehension, and instruction tuned scenarios. For example, in the MMLU (5-shot) benchmark, the LLaMA 3 70B model achieved a score of 82.0 compared to 52.9 by LLaMA 2 70B. Learn more in our detailed guide to Meta LLaMA 3.
Meta Code LLaMA 2
Meta AI has developed a family of large language models especially optimized for coding tasks, named Code LLaMA. These models fall into three main variants: the general-purpose Code LLaMA, Code LLaMA – Python tailored specifically for Python programming, and Code LLaMA – Instruct which is optimized for instruction-following and enhanced safety in deployment.
Each variant of Code LLaMA is available in four different sizes: 7B, 13B, 34B, and 70B parameters. The models input and output text, making them straightforward to integrate into existing workflows.
Like the general purpose LLaMA model, Code LLaMA is based on an optimized transformer framework, supporting a range of capabilities from basic code synthesis to advanced text infilling. The Code LLaMA 70B model supports a large context window of up to 100K tokens during inference.
Meta LLaMA Guard 2
Meta LLaMA Guard 2 is an advanced safeguard model built on the LLaMA 3 platform, with an 8B parameter setup. This model is designed to enhance the safety of interactions with LLMs by classifying both inputs to and outputs from LLMs. It functions by generating text outputs that classify the evaluated content as either safe or unsafe.
When content is deemed unsafe, LLaMA Guard 2 provides detailed categorizations of the violations based on predefined content categories. The model operates through a harm taxonomy, adapted from the MLCommons framework, which divides potential risks into 11 specific categories, ranging from violent and non-violent crimes to privacy breaches and sexual content.
How to Access LLaMA Models
Direct Download
LLaMA models can be accessed directly from Meta through the download form. Meta needs to review your request and approve it, which takes between a few hours and a few days. Upon approval, Meta provides a pre-signed URL and download instructions. The tools wget and md5sum must be installed on the machine to process the download script.
Using Ollama
Ollama offers a simplified way to run LLMs on Linux or macOS. To get a LLaMA model from the Ollama library, you’ll need to have Ollama installed on your computer. To run the model, use the relevant command. For example:
- For the 70B variant of LLaMA 3:
ollama run llama3:70b - For the 8B variant of LLaMA 3:
ollama run llama3 - For Code LLaMA (7B):
ollama run codellama
Note: Before using Ollama you still need to request access to the model as explained above.
Using Hugging Face
LLaMA models are also available from Hugging Face. In your Hugging Face account, you can choose the desired model and fill in your details. The model download page also provides information about the license agreement, which must be accepted. Meta then reviews the download request, which may take several days.
Upon approval, an email confirms your access to the Hugging Face repository for your requested model. Some files can be cloned directly to your local machine from the repository, while large files need to be downloaded from the file listed in the repository.
How Does Meta LLaMA 3 Compare to Other Leading LLMs?
Meta LLaMA 3 offers significant advancements in architecture, training data, scalability, and performance, compared to other open source LLMs and state of the art commercial LLMs.
Architectural Improvements
Meta LLaMA 3 employs a decoder-only transformer architecture with several notable enhancements. The model uses a tokenizer with a vocabulary of 128K tokens, leading to more efficient language encoding and improved performance. Additionally, the introduction of Grouped Query Attention (GQA) has optimized inference efficiency, enabling better handling of larger models without compromising speed or accuracy.
Training Data and Scale
The training dataset for Meta LLaMA 3 consists of over 15 trillion tokens, seven times larger than that used for LLaMA 2. This extensive dataset includes a significant portion of non-English data, enhancing the model’s multilingual capabilities. The diverse and high-quality data mix ensures robust performance across various domains, from trivia and STEM to coding and historical knowledge.
Performance and Benchmarking
Meta LLaMA 3 has demonstrated strong performance on numerous industry benchmarks. For instance, the 70B parameter model achieved a score of 82.0 on the MMLU (5-shot) benchmark, significantly outperforming its predecessor, LLaMA 2, which scored 52.9. The model’s improvements in post-training procedures have also reduced false refusal rates, improved alignment, and increased response diversity.
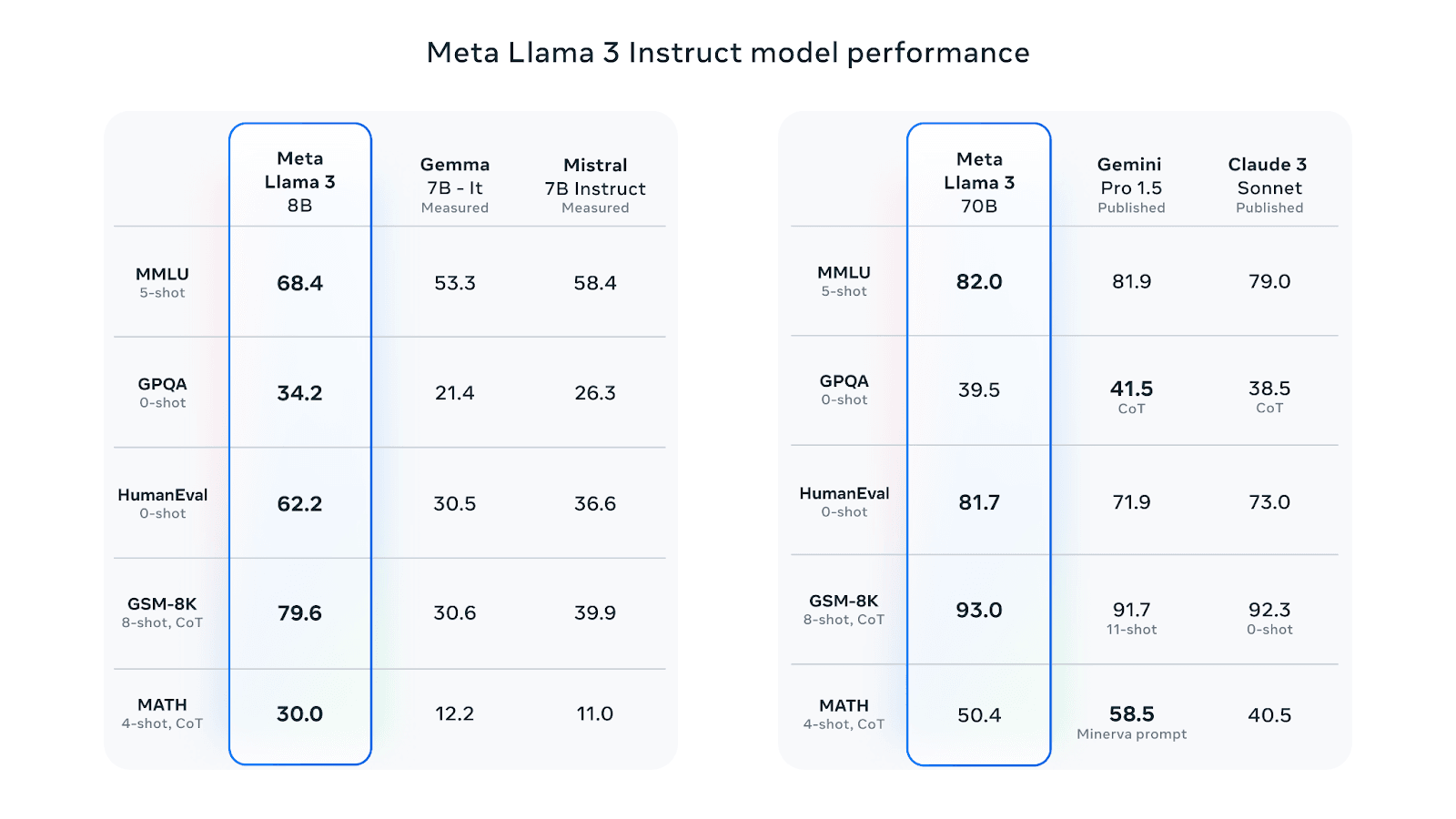
Source: Meta
Comparison with Proprietary Models
Compared to proprietary models like GPT-3.5 and Claude Sonnet, Meta LLaMA 3 excels in several areas. Benchmarks show improved performance, especially for the 70B model, across several use cases including reasoning, coding, and instruction following. According to Meta, beyond standardized benchmarks, the model consistently ranks higher in preference rankings by human annotators.
Future Developments
Meta has announced intentions to continue developing Meta LLaMA. Future releases will include models with over 400B parameters, enhanced multimodal capabilities, extended context windows, and multilingual support.
Meta LLaMA Alternatives: Notable Free LLM Tools
1. Mistral

Mistral is an AI technology platform offering open models and developer tools to enable rapid AI application development. It offers three primary models: Mistral 7B, Mixtral 8x7B, and Mixtral 8x22B. Mistral’s platform is built around providing high-performance, open-source AI models that can be freely used and adapted across various industries thanks to the permissive Apache 2.0 license.
Key features of Mistral include:
- Open source models: Provides a series of open models, such as the 7B and 22B sparse Mixture-of-Experts (SMoE).
- Multiple language support: Models are fluent in multiple languages including English, French, Italian, German, and Spanish, and have strong capabilities in processing code.
- Developer platform: Offers a portable platform for developers to build applications quickly using Mistral’s optimized models, with flexible access options.
- High-performance smaller models: Mistral models, like Mixtral 8x22B, outperform larger models in efficiency and speed, enabling faster performance with fewer parameters.
- Native function calling: Advanced models support native function calling and JSON outputs, enhancing integration and interaction capabilities within applications.
- Flexible deployment: Models can be deployed on Mistral’s EU-hosted infrastructure, via popular cloud platforms, or through self-deployment.
Related content: Read our guide to LLAMA 2 vs Mistral (coming soon)
2. Google Gemma

Google Gemma is a set of AI models designed for complex language understanding and generation tasks. Gemma is built on the same transformer architecture as Gemini, optimized for speed and accuracy in various applications. Variants include CodeGemma, PaliGemma, and RecurrentGemma.
Key features of Google Gemma:
- Extensive training data: Trained on a dataset encompassing diverse domains, enhancing its capability to handle a range of topics and languages.
- Advanced language understanding: Supports natural language processing tasks, including translation, summarization, and question answering.
- Multilingual support: Capable of understanding and generating text in multiple languages, making it suitable for global applications.
- Performance: Demonstrates high performance across standard industry benchmarks.
- Developer tools: Provides a suite of tools for easy integration and deployment, supporting cloud-based and on-premise implementations.
3. Smaug 72B

Smaug 72B is a high-performance language model developed by Abacus AI, designed for natural language understanding and generation tasks. It has an extensive parameter count and optimized architecture for diverse applications. On LLM leaderboards like HuggingFace, it has an average score over 80, comparing favorably with other open LLMs.
Key features of Smaug:
- Fine-tuned models: Available in various fine-tuned versions, optimized for specific tasks such as summarization, coding, and dialogue systems.
- Efficient architecture: Utilizes an optimized transformer architecture that balances performance and computational efficiency.
- Extensive training: Trained on a diverse dataset, ensuring accuracy and contextual relevance in responses.
- Scalable deployment: Supports flexible deployment options, from cloud platforms to on-premise solutions, catering to different user needs.
4. Vicuna

Vicuna offers an open-source chatbot, Vicuna-13B, designed to closely match the capabilities of leading AI models like OpenAI’s ChatGPT. Developed by fine-tuning the LLaMA model with 70,000 user-shared conversations from ShareGPT, Vicuna achieves more than 90% of the performance of ChatGPT-3.5 in informal evaluations.
Key features of Vicuna include:
- High-quality performance: Achieves over 90% of the quality of ChatGPT-3.5, surpassing other models like LLaMA and Stanford Alpaca in informal comparisons.
- Cost-effective training: Vicuna-13B was trained at a cost of approximately $300, making it a budget-friendly option for research and development.
- Open source availability: The code and model weights are available for non-commercial use, encouraging experimentation and further development by the community.
- Enhanced training data: Utilizes a large dataset of user-shared conversations, specifically tailored to improve chatbot responsiveness and relevance.
5. GPT4All

GPT4All is a privacy-conscious LLM chatbot that operates locally without requiring an Internet connection or a GPU. This free-to-use platform is designed for users who prefer maintaining privacy while interacting with AI, providing real-time inference even on lightweight devices like an M1 Mac.
Key features of GPT4All include:
- Runs locally: Can be installed and run directly on a user’s device, ensuring all data remains private and secure.
- No GPU or Internet required: Operates efficiently on standard CPUs without needing a GPU or an Internet connection.
- Multi-platform support: Available for Windows, MacOS, and Ubuntu with easy installation, ensuring broad compatibility.
- Versatile usage: Capable of performing a variety of tasks, including answering general knowledge questions, writing creative content, summarizing documents, and coding assistance.
- Real-time performance: Offers quick response times suitable for interactive use, enhancing user experience.
Source: GPT4All
{kind=link}
Building LLM Applications with LLaMA and Acorn
Visit https://gptscript.ai to download GPTScript and start building today. As we expand on the capabilities with GPTScript, we are also expanding our list of tools. With these tools, you can create any application imaginable: check out tools.gptscript.ai to get started.
See Additional Guides on Key Machine Learning Topics
Together with our content partners, we have authored in-depth guides on several other topics that can also be useful as you explore the world of machine learning.
Auto Image Crop
Authored by Cloudinary
- Auto Image Crop: Use Cases, Features, and Best Practices
- 5 Ways to Crop Images in HTML/CSS
- Cropping Images in Python With Pillow and OpenCV
Fine Tuning LLM
Authored by Acorn
- Fine-Tuning LLMs: Top 6 Methods, Challenges & Best Practices
- Parameter-Efficient Fine-Tuning (PEFT) Basics & Tutorial
- Fine-Tuning Llama 2 with Hugging Face PEFT Library
Anthropic Claude
Authored by Acorn