What Is an LLM Platform?
An LLM platform provides an environment for developing, deploying, and managing large language models (LLMs), such as OpenAI GPT, Anthropic Claud, and Meta LLaMA, and applications that rely on them. These platforms provide the necessary infrastructure, tools, and features to streamline the entire lifecycle of LLMs, from data preparation and model training to inference and monitoring.
LLM platforms are built to support various applications such as natural language processing (NLP), conversational AI, and generative AI, making it easier for organizations to integrate advanced language models into their products and services.
This is part of an extensive series of guides about AI technology.
How Does an LLM Platform Work?
An LLM platform creates a collaborative environment for LLM development, allowing teams to explore, save, and collaborate on language model applications. These platforms typically include the following key features:
- Collaborative prompt engineering: Teams can prototype completions, assistants, and workflows within the platform. This feature allows for tracking changes and integrating with product development workflows.
- Operational insights: Provides insights into usage and system performance across different features and teams. This helps in understanding user preferences, assessing prompt performance, and labeling data for further improvements.
- Retrieval augmented generation (RAG): Supports efficient search and retrieval of data from curated data sets, and using it to provide more relevant and accurate LLM responses.
- Fine-tuning custom models: Users can curate their best data to fine-tune custom models. This allows for the creation of specialized models tailored to specific tasks or industries.
- Data security: Ensuring the security of LLM training data and data input during inference, addressing concerns related to data privacy and compliance.
What Is LLMOps?
LLMOps, or Large Language Model Operations, is a set of practices and operational methodologies to manage and optimize applications based on LLMs. Similar to MLOps (machine learning operations), which focuses on the deployment and maintenance of ML models, LLMOps aims to simplify the lifecycle of LLMs from fine-tuning to deployment, monitoring, and maintenance.
LLMOps enables continuous iteration and improvement of LLMs, ensuring they remain effective and up-to-date. It involves fine-tuning models for specific tasks, using human feedback to enhance performance, and ensuring models comply with organizational and industry standards. The main benefits of LLMOps include increased efficiency, scalability, and risk reduction in managing LLMs.
Stages of LLMOps
The LLMOps process includes the following stages.
Exploratory Data Analysis (EDA)
Exploratory data analysis is useful for understanding and preparing the data that will be used to train, fine tune, or augment large language models. During this phase, data is collected from diverse sources, such as articles, images or video, and code repositories. The data is then cleaned to remove any inconsistencies, errors, or duplicates, ensuring its quality and relevance.
Data Preparation and Prompt Engineering
Data preparation includes the synthesis and aggregation of the cleaned data, transforming it into a format suitable for training. This step might involve pre-processing data, generating embeddings, and segmenting data into training, validation, and test sets.
Prompt engineering involves creating prompts that will guide the model during training and inference. Effective prompt engineering ensures that the LLM can understand and respond to various input types accurately, enhancing its ability to generate meaningful and contextually appropriate text.
Model Fine-Tuning
Model fine-tuning tailors pre-trained LLMs to specialized tasks or domains by adjusting the model’s parameters based on a targeted dataset. This involves using libraries and frameworks such as Hugging Face Transformers to modify the model for improved performance in specific applications.
Fine-tuning enhances the model’s ability to generate accurate, relevant, and high-quality responses. It also includes hyperparameter tuning, which optimizes aspects like learning rate and batch size to further refine the model’s performance. This stage is iterative, often requiring multiple rounds of adjustments and evaluations to achieve optimal results.
Model Review and Governance
Model review and governance are essential for ensuring that the LLM operates safely, ethically, and effectively. This stage involves rigorous testing to identify and mitigate biases, security vulnerabilities, and other risks. Governance includes setting policies and procedures for model usage, performance tracking, and compliance with legal and ethical standards.
Continuous monitoring and documentation are important to maintain transparency and accountability. By managing the model throughout its lifecycle, including updates and eventual deprecation, governance ensures that the LLM remains aligned with organizational goals and regulatory requirements.
Model Inference and Serving
Model inference and serving involve deploying the trained LLM into a production environment where it can generate text or answer queries in real time. This stage requires setting up infrastructure to host the model, such as cloud services or on-premises servers, and providing APIs for easy integration with applications.
Inference involves running the model on new data inputs to produce outputs, which can be done through REST APIs or web applications. Effective serving ensures low latency, high availability, and scalability, enabling the LLM to handle large volumes of requests. This stage also includes periodic model updates to incorporate new data and improvements.
Model Monitoring with Human Feedback
Model monitoring with human feedback is a continuous process aimed at maintaining and enhancing the performance of deployed LLMs. This involves tracking various performance metrics, such as accuracy, response time, and user satisfaction. Monitoring tools can detect anomalies, degradation in performance, or unexpected behaviors.
Human feedback provides insights into the model’s real-world performance and highlights areas for improvement. Reinforcement learning from human feedback (RLHF) can be used to retrain the model, incorporating users’ inputs to refine its responses.
10 Notable LLM Platforms
1. Cohere AI

Cohere AI is an enterprise AI platform that focuses on generative AI, search and discovery, and advanced retrieval to optimize operations across various sectors.
Features:
- Enterprise gen AI with Cohere Command: Enables the creation of scalable, efficient, and production-ready AI-powered business applications.
- Data embedding with Cohere Embed: Generates embeddings for data in over 100 languages. This model is trained on business language to ensure more appropriate responses.
- Accurate response surfacing with Cohere Rerank: Enhances application responses by providing the most reliable and up-to-date information. Paired with Embed, it enables generation of responses that are directly relevant to an organization’s data needs.
- Retrieval capabilities: The integration of generative AI with advanced retrieval models supports powerful applications requiring retrieval-augmented generation (RAG).
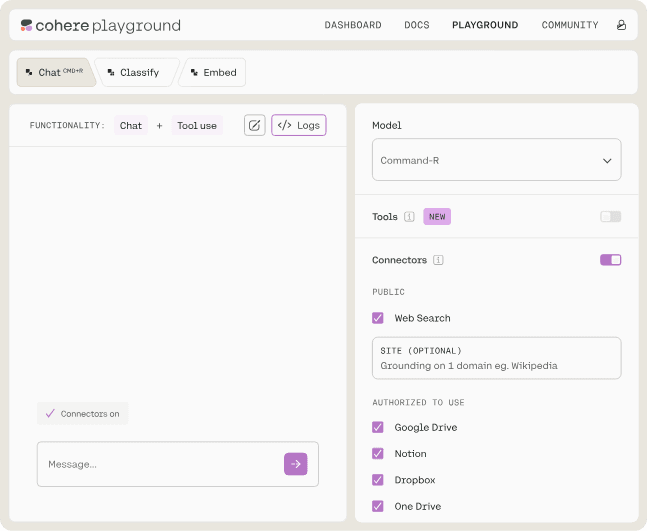
Source: Cohere AI
{kind=link}
2. Lamini

Lamini is an enterprise-grade LLM platform designed to simplify the entire model refinement and deployment process for development teams. It supports model selection, tuning, and inference usage, making it more accessible for companies to leverage open-source models with their proprietary data.
Features:
- Model accuracy enhancement: Offers memory tuning tools and compute optimizations allowing users to fine-tune any open-source model with company-specific data.
- Deployment flexibility: Users can host their fine-tuned models in various environments—whether in a private cloud (VPC), a data center, or directly through Lamini.
- Inference optimization: Makes LLM inference straightforward with GPUs and supports optimizing performance on user-owned hardware, delivering high-throughput inference capabilities at any scale.
- Model lifecycle support: From initial model comparison in the Lamini Playground through deployment, provides a full suite of tools including REST APIs, a Python client, and Web UI for each step of the model lifecycle—chatting with models, tuning with proprietary data, deploying securely anywhere, and serving optimized inference.
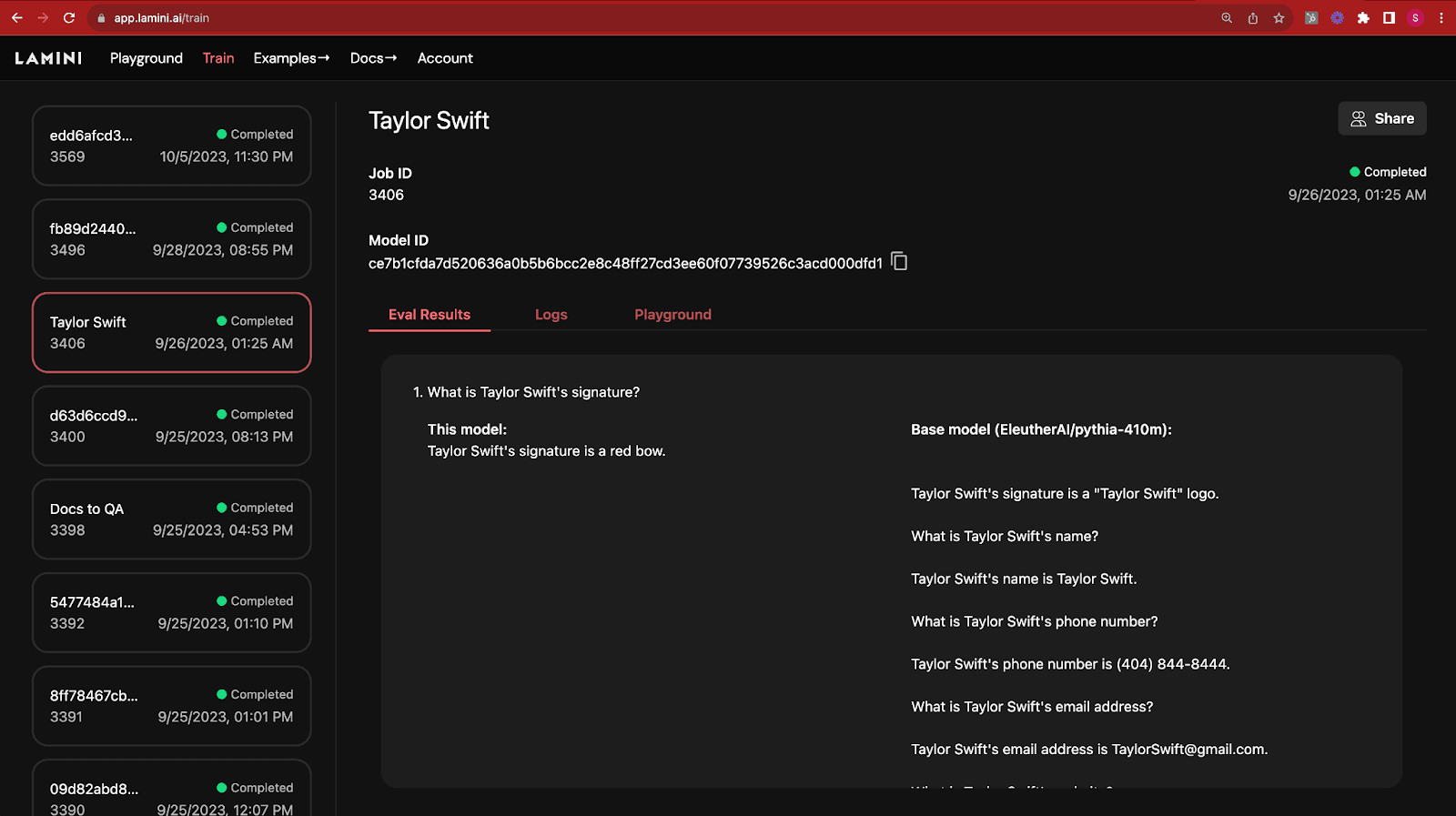
Source: Lamini
{kind=link}
3. Aisera

Aisera is an AI service platform for enterprise use. It integrates advanced AI and machine learning technologies to automate various business processes, offering solutions like AiseraGPT and AI Copilot for enhanced efficiency in operations. For a deeper dive on Aisera solutions check out our overview of Aisera.
Features:
- UniversalGPT: Automates tasks, workflows, and knowledge across all domains. This feature enables enterprises to significantly enhance their operational efficiency by reducing manual interventions in routine tasks and ensuring that actions are taken swiftly and accurately.
- AI Copilot: Serving as an AI concierge, offers prompt and workflow customization options. Enterprises can tailor the AI’s responses and actions according to their needs.
- AI Search: Designed for enterprise-wide applications, the search feature is powered by large language models (LLMs), providing personalized and privacy-aware search functionalities.
- Agent Assist: Aimed at supercharging agent productivity, this feature provides answers, summarizations, next-best actions, and in-line assistance. By equipping customer support agents with these tools, organizations can ensure faster resolution of customer queries.
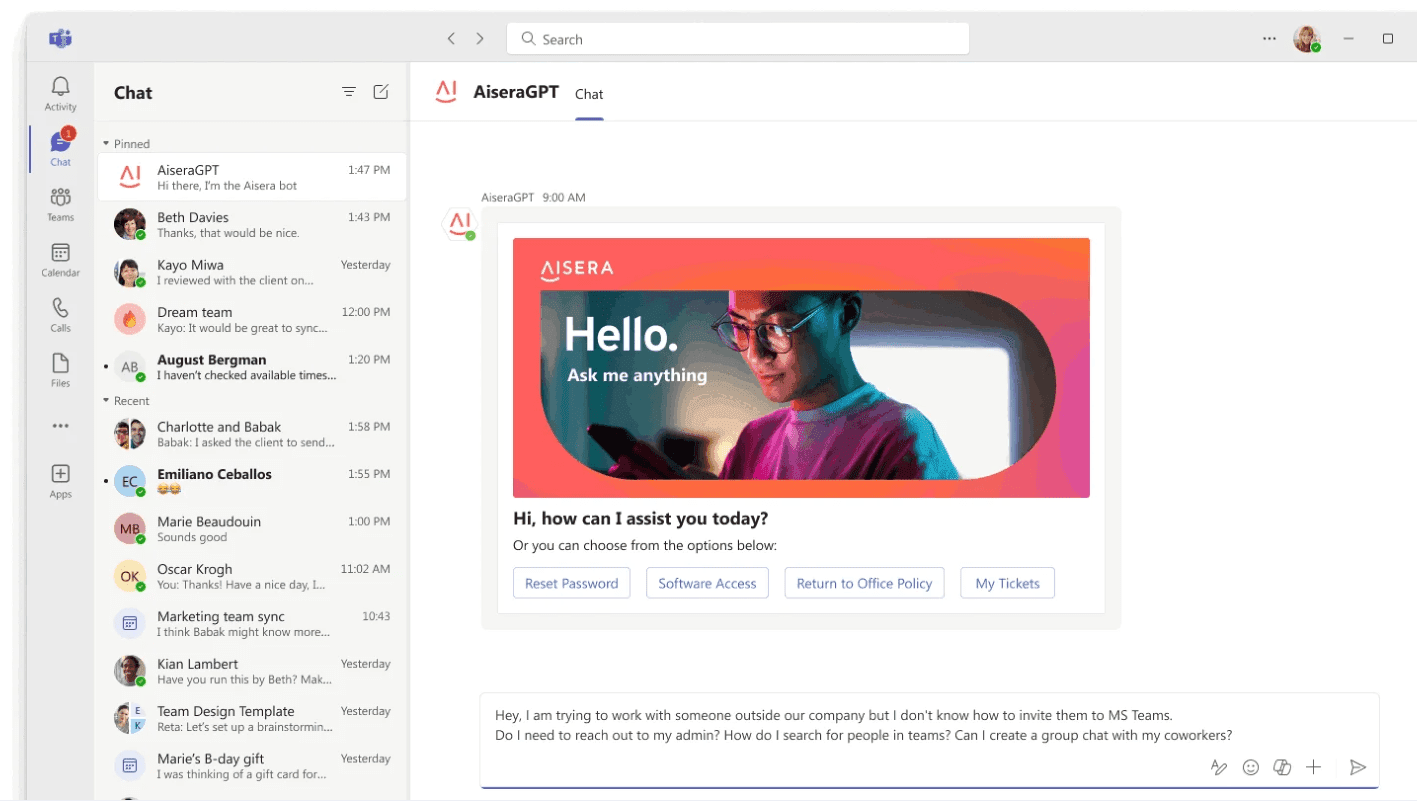
Source: Aisera
{kind=link}
4. MindsDB

MindsDB is intended to democratize AI and machine learning, enabling organizations to harness predictive analytics directly within their database environments. It integrates with existing data sources and provides tools for automated machine learning workflows.
Features:
- Automated fine-tuning: Automatically updates models with real-time enterprise data, ensuring predictions remain accurate over time. This feature is crucial for businesses that rely on up-to-date information for decision-making, as it eliminates the need for manual model retraining.
- AI-powered data retrieval: Supports features like embeddings sync, RAG (retrieval-augmented generation), and semantic search. These capabilities enhance the versatility of data retrieval processes, allowing for more efficient and contextually relevant searches across large datasets.
- Predictive analytics using SQL: Enables users to perform complex predictive analytics tasks using just SQL queries. This democratizes access to advanced analytics by leveraging a familiar language, making it easier for analysts without deep technical expertise in machine learning.
- In-database machine learning: By deploying AI models at the data layer and enabling inference with SQL, MindsDB supports the integration of machine learning into existing databases. This reduces the complexity of deploying AI models.

5. Databricks Mosaic AI

Databricks Mosaic AI serves as a unified platform for the development, deployment, and monitoring of AI and ML solutions. It simplifies the entire lifecycle of predictive modeling and generative AI applications, including large language models. Leveraging the Databricks Data Intelligence Platform, Mosaic AI enables secure integration of enterprise data into AI workflows.
Features:
- Unified tooling: Provides a cohesive environment for building and deploying ML and GenAI applications. It supports the creation of predictive models as well as generative AI and LLMs.
- Cost efficiency: The platform allows training and serving of custom LLMs at a significantly lower cost. Organizations can develop their own domain-specific models at up to 10x less expense compared to traditional methods.
- Production quality assurance: Organizations can deliver high-quality, safe, and governed AI applications. The platform ensures that deployed solutions meet stringent standards for accuracy and governance.
- Data control: Users maintain full ownership over their models and data throughout the process. This is crucial for enterprises concerned with data security and intellectual property rights.

Source: Databricks
{kind=link}
6. Qwak

Qwak is a unified AI platform for simplifying the development, deployment, and management of machine learning and large language models. It integrates MLOps, LLMOps, and feature store capabilities into a single platform.
Features:
- Unified AI/ML lifecycle management: Provides a centralized model management system that supports the entire lifecycle of AI/ML models, from research to production.
- LLMOps capabilities: Includes tools for developing and managing LLM applications. This involves managing prompts with a single registry, facilitating prompt creation, deployment, experimentation, version tracking, and offering a prompt playground for testing and iteration.
- Scalable model deployment: Supports the deployment and fine-tuning of various models, including embedding models and open-source LLMs. The platform offers flexibility in deployment, allowing users to host models on Qwak’s cloud infrastructure or their own.
- Feature store integration: Qwak’s feature store manages the entire feature lifecycle, ensuring consistency and reliability in feature engineering and deployment.
Source: Qwak
{kind=link}
7. Lightning AI

Lightning AI is a platform designed for the development, training, and deployment of AI models, including LLMs, across a cloud-based infrastructure. It simplifies the process of working with artificial intelligence by providing tools and resources that enable users to prototype, train, deploy, and host AI web applications directly from their browser.
Features:
- Zero setup development environment: Helps developers interact with machine learning by offering a zero setup development environment. This allows users to start projects instantly without worrying about configuring Python, PyTorch, NVIDIA drivers, or other dependencies traditionally required for AI development.
- Training multi-node models: Users can scale their model training across multiple nodes in seconds.
- Rapid prototyping: Accelerates the prototyping phase for machine learning projects.
- GPU management: Makes it easier to changing computational resources from CPU to GPU. Users can switch between different processing units without needing to manage file transfers or environment configurations manually.
Source: Lightning AI
{kind=link}
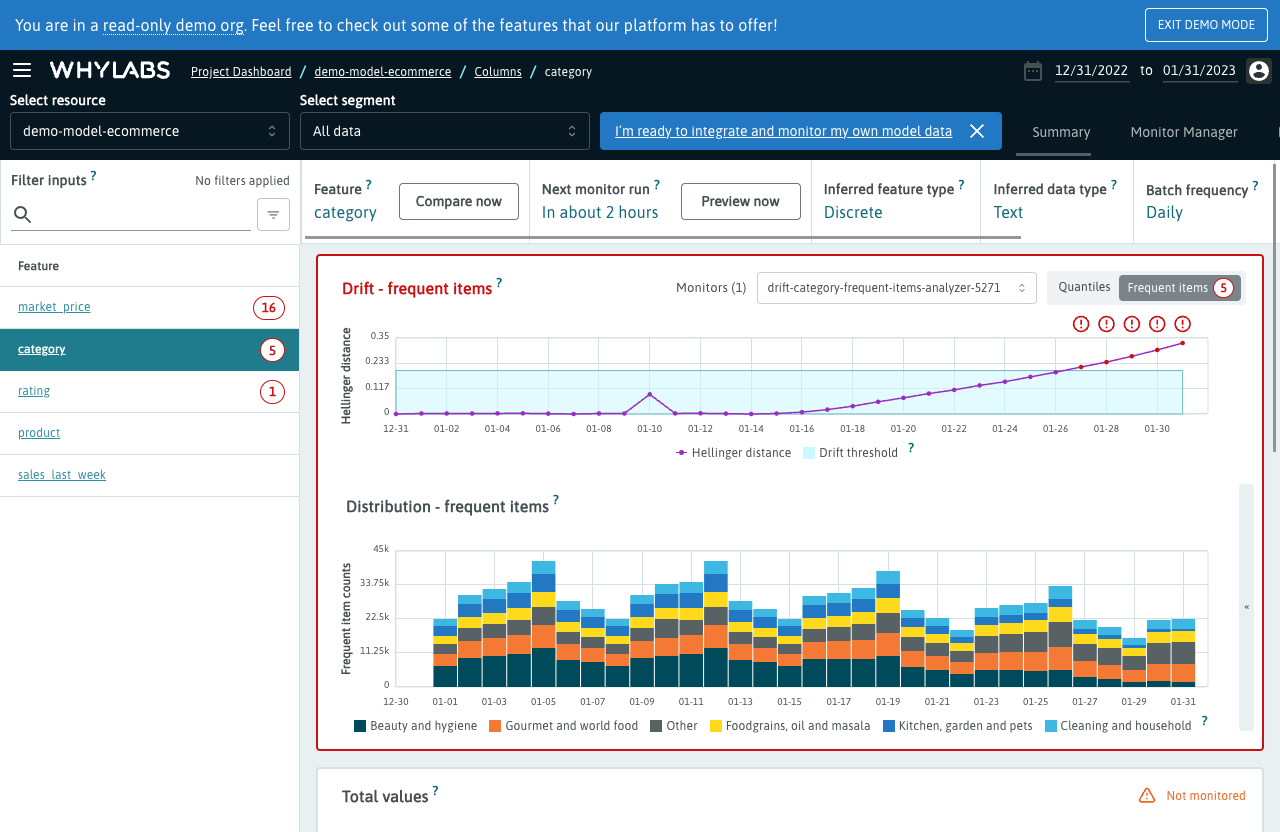
8. WhyLabs

WhyLabs is a platform dedicated to monitoring, debugging, and operating AI models at scale, addressing the lifecycle challenges of machine learning in production environments. It provides data observability solutions that help teams maintain model performance by identifying issues in real time, ensuring the reliability and accuracy of AI applications.
Features:
- Automated anomaly detection: Uses advanced algorithms to automatically detect anomalies in model input data or behavior. This enables teams to address potential issues before they impact model performance or end-user experiences.
- Data observability: Offers detailed visibility into data pipelines and model inputs/outputs, enabling a deep understanding of model functioning and data health.
- Model drift detection: Can identify and alert on signs of model drift, where a model’s performance degrades over time due to changes in underlying data patterns.
- Scalable architecture: Designed for scalability, supports monitoring of AI applications across various deployment environments, from on-premises servers to cloud-based infrastructures. Its architecture ensures that as models scale, monitoring capabilities can grow accordingly.
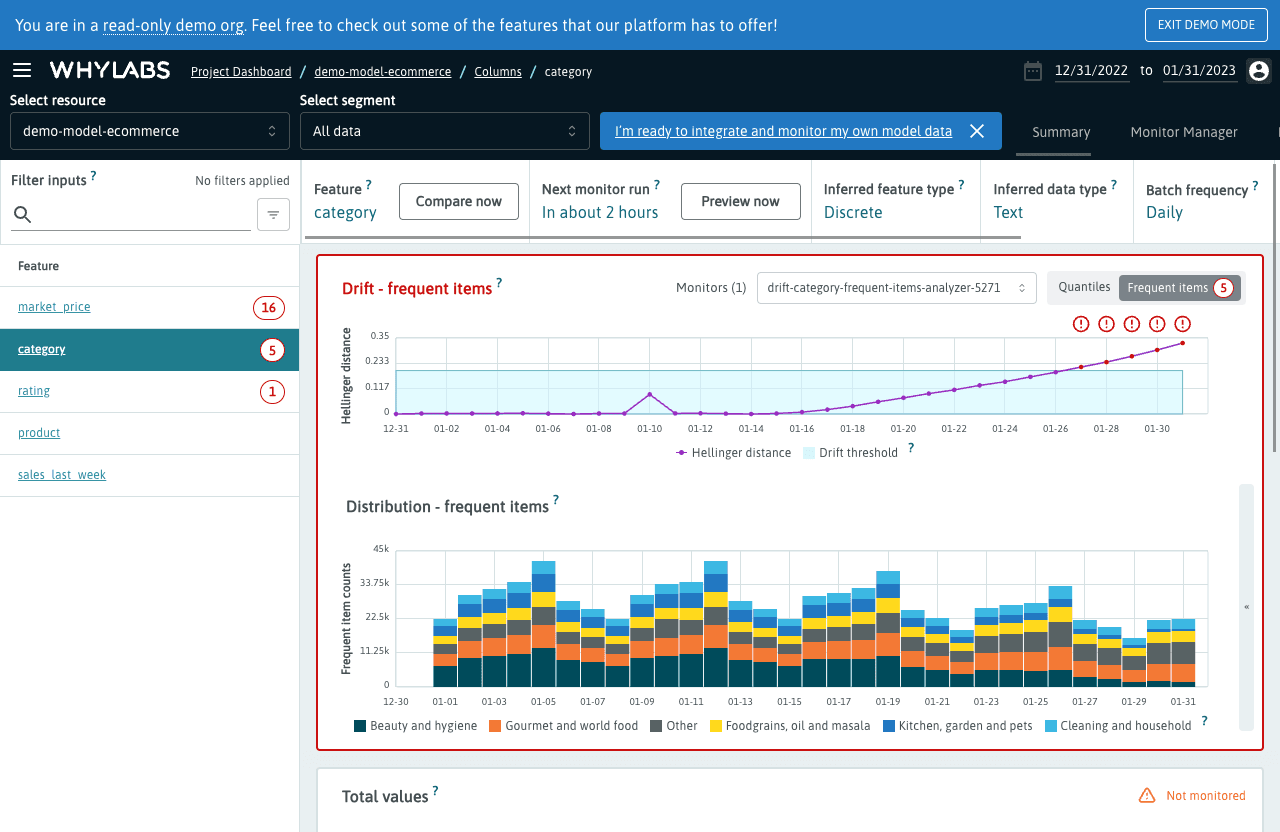
Source: WhyLabs
{kind=link}
9. NVIDIA Nemo

NVIDIA NeMo is a scalable and cloud-native generative AI framework for researchers and PyTorch developers working in LLMs, multimodal models, automatic speech recognition (ASR), text-to-speech (TTS), and computer vision. The framework supports the efficient creation, customization, and deployment of generative AI models using existing code and pre-trained model checkpoints.
Features:
- Scalable training: All NeMo models are trained using Lightning and can scale automatically across thousands of GPUs. The framework using distributed training techniques like tensor parallelism (TP), pipeline parallelism (PP), fully sharded data parallelism (FSDP), mixture-of-experts (MoE), and mixed precision training with BFloat16 and FP8.
- NVIDIA transformer engine: Uses FP8 training on NVIDIA Hopper GPUs and NVIDIA Megatron Core for scaling Transformer model training.
- Alignment techniques: Supports methods such as SteerLM, direct preference optimization, and reinforcement learning from human feedback.
- Parameter efficient fine-tuning (PEFT): Includes techniques like LoRA, P-Tuning, Adapters, and IA3 for fine-tuning models efficiently.
- Speech AI integration: NeMo ASR and TTS models can be optimized and deployed for production use cases with NVIDIA Riva.
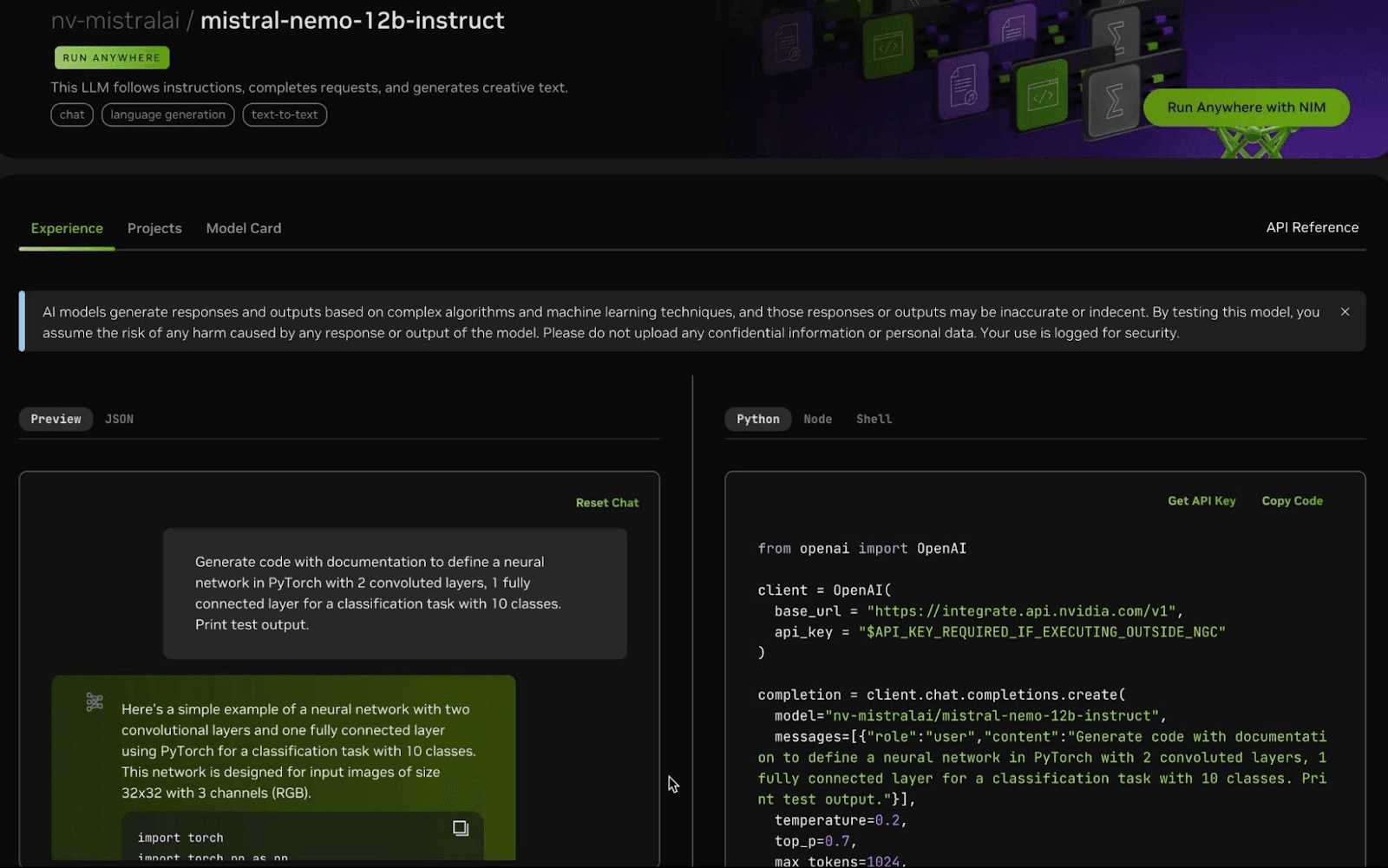
Source: NVIDIA
{kind=link}
Conclusion
LLM platforms are transforming the landscape of natural language processing by providing frameworks for generating, interpreting, and utilizing human language. These platforms enable a wide array of applications, from conversational agents and content generation to advanced data retrieval and predictive analytics.
By integrating features such as collaborative prompt engineering, retrieval-augmented generation, and secure data handling, LLM platforms simplify the development, deployment, and management of language models, ensuring they remain effective and adaptable to various industry needs. As the technology evolves, LLM platforms will continue to enhance their capabilities, driving innovation and efficiency in numerous sectors.
Learn more about Acorn for LLM development
See Additional Guides on Key AI Technology Topics
Together with our content partners, we have authored in-depth guides on several other topics that can also be useful as you explore the world of AI technology.
AI Cyber Security
Authored by Exabeam
- AI Cyber Security: Securing AI Systems Against Cyber Threats
- AI Regulations and LLM Regulations: Past, Present, and Future
- Artificial Intelligence (AI) vs. Machine Learning (ML): Key Differences and
Examples
Open Source A
Authored by Instaclustr
- Top 10 open source databases: Detailed feature comparison
- Open source AI tools: Pros and cons, types, and top 10 projects
- Open source data platform: Architecture and top 10 tools to know
Vector Database
Authored by Instaclustr